
Spend long enough at any modern company, and you will have had this dreaded experience: Someone within your organization, be they a leader with eyes on improved efficiency, or a security team plugging a newly found leak, throws a new piece of software into the mix with little warning.
People across your team end up scrambling. They sit through haphazard training sessions, or sift through exhaustive documentation, and despite it all, the new shiny tool ends up unused. Or, end users find the new solution so cumbersome and confusing that the team who bought it – or worse, the team that is simply charged with maintaining it – spends all of their time troubleshooting rather than doing their actual job.
When you speak with CIOs, you will hear that these are generally viewed as the worst case scenarios for any piece of software that is brought into an organization. A failed or scattershot implementation erodes trust between different functions, wastes company budget, and fails to address the issue the tool was meant to solve in the first place.
Unfortunately, from speaking with many data teams, we often hear the same story of haphazard software adoption being emulated when it comes to their data technologies.
Steve Jobs explained this tendency to emphasize ideas over implementation in reflecting on one of the challenging periods in Apple’s history, saying, "it's the disease of thinking that a great idea is 90% of the work … it is that process that is the magic.” While Jobs was talking about building rather than implementing products, we agree that the success of initiatives is not their idea, but rather the magic of the journey.
We would like to suggest that data teams begin to organize their enablement efforts, as well as the success of their data initiatives, around a “customer journey.” By viewing and measuring their efforts in this way, data teams can avoid the pitfalls associated with software that becomes “shelfware,” or which ultimately results in unhappy end users. If data is a product, the people who consume it should be supported and enabled like any customer.
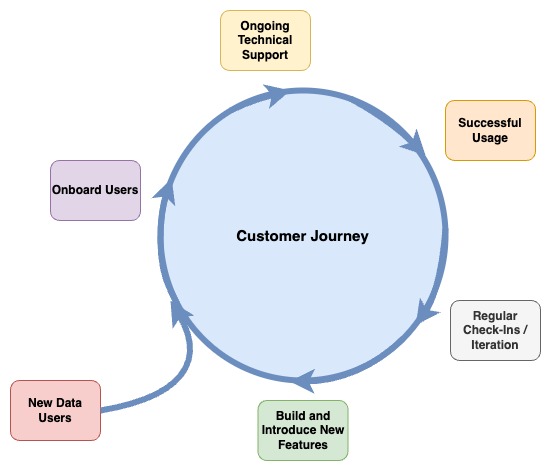
A simple way to start thinking about what it means to empower end users is to consider what context a new employee will need in order to use a specific tool after they join the company.
The worst version of this, across both software and data assets, is to simply point the user toward an intranet, or a help center, and to have them read all the documentation there. Why doesn’t this work?
Intranets are great ways of storing lots of information, especially when that information is hierarchical in nature. However, the information is also decontextualized, lacking all but the most basic reference points for why the information they contain is important. Without this context, new users are unlikely to retain much of what they read.
Training documentation is important, but it should be only one piece of an overall strategy that emphasizes context, and puts real business priorities front and center. This doesn’t mean you have to provide hours-long live training sessions to every person who joins the organization – the best teams employ a variety of approaches, including live sessions, in-context guides, and documentation.
The style of training should support end users with different learning styles and levels of comfort using data. For some, a more hands-on session may be necessary, while others might prefer a Pendo- or Appcues- style guide that allows them to walk step-by-step through your dashboards on their own time. Many teams will create self-guided challenges that ask users to use tools like Looker Explores to solve a problem, in order to familiarize them with the available resources.
Whatever exact form your training strategies take, they should always be designed with scalability and self-service at the top of mind, so that you can provide context without necessarily needing a member of your data team in the room, or available in a Slack channel.
Even the best tools require some form of ongoing support. Things break, customers will have ad hoc requests, and after using something for a long time, the basics of training can feel far away.
When building data products, analytics teams need to keep this ongoing support in mind. While having flows for issues with asset quality is important, support means more than bug fixes; it means that users always have the tools they need to appropriately contextualize data, and drive insights from it.
The most common solutions for ongoing support are to either shunt the user to an intranet that may or may not have the answer the user needs, or to use one of the oldest fallbacks: the service desk. We have discussed extensively on this blog how service desk models are broken, and how they lock data teams into transactional power dynamics with stakeholders.
Viewed through the lens of software customer enablement, there is another reason why relying too heavily on the service desk model is a bad idea: service desks are inherently reactive, while enablement should be proactive.
You do need a fallback if someone has a question that truly cannot be answered without a member of the data team stepping in. However, if users are needing to ask these questions with any level of frequency, it indicates that the end user is already not fully enabled. Proper enablement results in self-sufficiency.
Rather than focusing on answering questions as they come up, data teams can save time and encourage self-sufficiency by implementing different forms of ongoing training. To illustrate why this is necessary, think about some of the possible circumstances your team might find themselves in:
There are a lot of potential approaches to this ongoing training. You could host lunch and learn sessions, drop-in office hours, or make Loom videos available for a dashboard that raises a lot of questions.
For more self-service oriented teams, offering to review dashboards created by users can also be a way to make sure your analytics tools are being used correctly, and with the appropriate context. Ted Conbeer, the Chief Data Officer at Privacy Dynamics, discussed this approach on a recent episode of our Data Knowledge Pioneers podcast:
“In almost every interaction with my stakeholders across the business and Product and Ops and Marketing, I would just repeat this over and over again. If you ever don't know, or if you don't use the dashboard every day and you just found something and you want to build something new, just send it to me. Because I can take 15 minutes and probably tell you if it's close to right or not. But if you never send it to me, if you never ask, I'll never know.”
Every training initiative is of course dependent on your team’s staffing and the organizational culture around your data. But the more options you have where your end users can keep up with ongoing changes and be reminded what is actually valuable, the better enabled they will be.
The impact of data teams is often measured by how much they build, and how quickly they can put crucial data in front of end users.
But even the best teams have rolled out new dashboards or self service assets that seem like they will be of value, only to find that no one uses them. It turns out, how you launch a new feature or asset is just as crucial as what you launch.
Again, we can take our lead from the customer journey through software adoption to understand how to avoid this scenario:
This may seem like a lot of extra work to throw on top of building the data products that your organization uses on a day-to-day basis, but the process of empowering your end users speaks to one of the possibly less glamorous truths about data: success is not just about what you build, it is about how what you build is used.
Just as a poorly implemented software solution can wind up as shelfware, all of your efforts to build engaging data assets can be for nothing without proper enablement.
By treating your end users as customers, though, and putting a multi-faceted enablement strategy in place, your analytics team can make sure all your efforts directly contribute to the success of everyone in the business.

In this article, we discuss how data-driven teams can tame entropy and empower stakeholders with a single access plane for analytics.

Data asset entropy has been an issue for as long as data has been used in decision making. But in the modern organization, where analytics tools have exploded in number and type, entropy has become a huge stumbling block to effective data-driven operations.

The goal of your workflow is not just to uncover valuable wisdom from your data. It is crucial to communicate those actionable data observations to the organization which can use them to make decisions.
Receive regular updates about Workstream, and on our research into the past, present and future of how teams make decisions.


